 Tom McLaughlin
Tom McLaughlin

This is Part 4 of the series Hello Serverless, a guide aimed at the individual or team that is building their first serverless application. This series addresses the common conceptual and tactical questions that occur during the serverless development and operational lifecycle. This post covers the Hello Serverless application’s evolution from a serverless monolith to serverless functions.
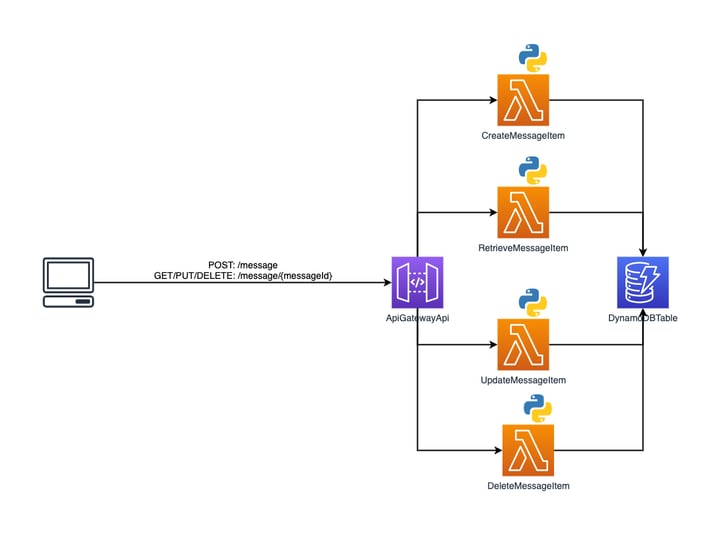
Now it’s time for us to break down Hello Serverless from a serverless monolith into separate functions. In this architecture, each CRUD operation will be a separate Lambda function. Our application will no longer consist of API Gateway proxying all requests to a single Lambda function that executes the appropriate code based on its route configuration. Instead, when a REST endpoint defined by API Gateway receives a request, a specific Lambda function will execute.
This is what the new serverless functions design will look like, and the code for the application can be found here on GitHub.
What Do We Mean By Serverless Functions?
What do we mean by serverless functions? The previous serverless monolith had a serverless function. What is differentiating here? What I mean by serverless functions is breaking down separate application operations into separate serverless functions as opposed to having a single serverless function that handles all application operations.
There are several benefits of breaking the application down into independent functions. To start, we’re going to shed a lot of code from our application. We will entirely remove the Flask framework from Hello Serverless. Next, the code separation through the use of multiple serverless functions reduces the impact of bugs or failures in one area of code that affect other application operations. The AWS SAM CLI will also package each Lambda function independently, which means each Lambda function can be updated independently. Just like breaking down an application monolith into microservices allows us to scale services independently, we can now scale individual functions independently. For example, our serverless runtime platform might run more function instances for creating message items than deleting message items. Also, while not relevant to us, if an application operation requires more memory or compute than others then we can scale that serverless function’s resource utilization independent of the other serverless functions. Multiple functions can also make certain operational practices simpler, for instance AWS will create separate log CloudWatch log groups for each function, which can be monitored independently. This makes it quicker and easier to isolate which application operation is exhibiting issues.
There are, of course, drawbacks to adopting multiple serverless functions. The primary drawback is a lack of familiarity with the design. The patterns for building non-serverless web services are largely understood, which is why this series started with a Python Flask application. We separated routes, models, and shared code as someone building a backend web API might routinely do. The structure of our application in this post will be different. We are actually going to combine route and model logic into the application’s serverless functions. Plus, we’re going to have to share code between serverless functions differently. This results in a learning curve. It’s not insurmountable, but people are going to stumble. There are decisions in this version of the application that are the result of my own trial, error, and learning. I settled on how I structure a multi-function serverless application over years of experience.
Neither a serverless monolith nor serverless functions is right or wrong. Which approach to use will be dependent on what you are building and who will be building it. My own preference is for the serverless functions approach about to be described. I think the approach allows for greater flexibility in choosing the best event source for each application operation. It also lets you remove application code and replace it with other managed services from a cloud provider. Application code should be seen as a liability. Code needs to be maintained and it’s a source of potential errors. The less doee there is, the less code to make a mistake in and adversely impact the application. Plus functionality that’s been moved to managed service configuration is arguably easier to audit than application code and some cloud service providers provide tools for auditing service configuration.
However, the recent reexamination of microservices versus monoliths in the container world also applies to the functions versus monolith discussion in the serverless world. Microservices create increased architecture complexity compared to monoliths. The same applies when adopting a serverless functions approach over a serverless monolith, you have to be aware of the complexity and ready to manage it. If you cannot manage your existing containerized microservices architecture properly, a functions approach is going to introduce even more complexity than you are already unable to manage.
Creating Serverless Functions
Here is how the application has been restructured to break it down into separate functions.
./
├── LICENSE
├── Makefile
├── Pipfile
├── Pipfile.lock
├── README.md
├── diagram.png
├── events
│ ├── CreateMessageItem-event.json
│ ├── CreateMessageItem-msg.json
│ ├── DeleteMessageItem-event.json
│ ├── DeleteMessageItem-msg.json
│ ├── RetrieveMessageItem-event.json
│ ├── UpdateMessageItem-event.json
│ └── UpdateMessageItem-msg.json
├── pytest.ini
├── samconfig.toml
├── src
│ ├── common
│ │ ├── common
│ │ │ └── __init__.py
│ │ └── setup.py
│ └── handlers
│ ├── CreateMessageItem
│ │ ├── __init__.py
│ │ ├── function.py
│ │ └── requirements.txt
│ ├── DeleteMessageItem
│ │ ├── __init__.py
│ │ ├── function.py
│ │ └── requirements.txt
│ ├── RetrieveMessageItem
│ │ ├── __init__.py
│ │ ├── function.py
│ │ └── requirements.txt
│ └── UpdateMessageItem
│ ├── __init__.py
│ ├── function.py
│ └── requirements.txt
└── template.yamlThe MessageCrud Lambda function has now been replaced by four Lambda functions that represent the application’s create, retrieve, update, and delete operations. These functions are CreateItemMessage, RetrieveItemMessage, UpdateItemMessage, and DeleteItemMessage, and they are in separate directories under src/handlers/. With more Lambda functions, now the decision to place MessageCrud under src/handlers/ makes a little more sense.
Each of these Lambda function directories has a function.py file that contains all of the function’s code. To put that in perspective, think of how code was broken down previously for, say, the create operation. The route definition and request logic were in app/routes/message.py and the business logic to create a message item in DynamoDB was in app/models/message.py. Instead of spreading that logic across multiple files, it is now all contained in function.py, which we’ll dive into shortly. Finally, each function has its own requirements.txt file because each Lambda function is packaged separately and therefore needs to specify its own code dependencies.
The src/common/ directory contains a package named common where code common to all Lambda functions in the application can be packaged and included as a dependency of each Lambda function. All of our functions have this package included in their requirements.txt file so it is included just like any other application dependency. While splitting up our monolithic Lambda function reduces the amount of shared code that can impact the different application operations, there are still uses for shared code across functions.
Application Initialization & Route Definitions
In the previous application examples, initialization was split between two files: one file initialized the application and the other served as the entry point to the web server or API Gateway and served the application up. That code no longer exists. There is no single application to initialize and serve up, just independent functions. So what triggers these functions to execute?
We’re going to see code replaced with SAM configuration. We’ll do away with both the application initialization and route definition code and replace it with configuration in template.yaml. In the previous serverless monolith approach, we saw our application code barely change. But by moving to a serverless functions approach, we’ll see the application shed code.
In the serverless monolith, the template.yaml file had a single AWS Lambda function defined. Now, there will be an AWS Lambda function defined for each of this application’s four functions. What’s the same and what’s changed? Below is the configuration for the RetrieveMessageItem Lambda function.
Type: AWS::Serverless::Function
Properties:
Description: "Get message item in DDB"
CodeUri: src/handlers/RetrieveMessageItem
Handler: function.handler
Runtime: python3.8
MemorySize: 128
Timeout: 3
Policies:
- Statement:
- Effect: "Allow"
Action:
- "dynamodb:GetItem"
Resource:
Fn::GetAtt:
- DynamoDBTable
- Arn
Environment:
Variables:
DDB_TABLE_NAME: !Ref DynamoDBTable
Events:
ApiGateway:
Type: Api
Properties:
Path: /message/{message_id}
Method: GET
RestApiId: !Ref ApiGatewayApiThe CodeUri property has been updated to reflect the function’s location. Next, the Handler property is the same but has changed behind the scenes. In the function.py file, handler is not the name of the variable that represents the application instance but is a Python function instead. We’ll look at the handler function in more depth shortly.
Next, we move onto the Policies property where the number of DynamoDB actions the function can perform has been reduced to the only action RetrieveMessageItem needs, dynamodb:GetItem. By splitting our code into separate functions, we can practice a policy of least privileged access, and we can better understand the bounds of what the code does and ask appropriate questions when IAM policy statements do not match expectations. If the RetrieveMessageItem created or altered data, we would have reasonable questions as to why.
Now come down to the Events property where we build off of a change introduced with the serverless monolith. The serverless monolith was triggered by API Gateway and it proxied all paths for any HTTP method, and our application’s code had Python decorators that defined the application’s REST endpoints. With our functions approach, we specify that an HTTP GET request to /message/{message_id}, where message_id is a path parameter variable, will trigger this Lambda function.
What we have done by turning our application into multiple AWS Lambda functions is removed our application’s initialization and route definition code and replaced it with simple configuration declared in our SAM template. This is only the tip of the iceberg, too. As you get deeper into API Gateway, you will find more application code you can remove and even potentially entire Lambda functions you can do away with.
Request Logic & Business Logic
Previously, we separated request logic and business logic between app/routes/message.py and app/models/message.py. The first file had functions that handled a request by extracting any relevant information from the request and passing it to the appropriate function in the second file. We divided our application’s code based on its role in the codebase. In breaking this application up into multiple Lambda functions, we’re breaking down the code instead based on application functionality. That means we’re going to combine, for example, the code for handling a create request with the code for creating an item in DynamoDB in the function.py file for the CreateMessageItem Lambda function (though we will keep some separation between the two). Here’s the code for CreateMessageItem.
src/handlers/CreateMessageItem/function.py
'''Put item in DDB'''
import json
import logging
import os
from datetime import datetime
from uuid import uuid4
import boto3
# This path reflects the packaged path and not repo path to the common
# package for this service.
import common # pylint: disable=unused-import
DDB_TABLE_NAME = os.environ.get('DDB_TABLE_NAME')
ddb_res = boto3.resource('dynamodb')
ddb_table = ddb_res.Table(DDB_TABLE_NAME)
def _create_item(item: dict) -> dict:
'''Transform item to put into DDB'''
dt = datetime.utcnow()
item['pk'] = str(uuid4())
item['sk'] = 'v0'
item['timestamp'] = int(dt.timestamp())
ddb_table.put_item(
Item=item
)
return {'message_id': item['pk']}
def handler(event, context):
'''Function entry'''
message = json.loads(event.get('body'))
message_id = _create_item(message)
body = {
'success': True,
'message': message_id
}
resp = {
"statusCode": 200,
"body": json.dumps(body)
}
return respThe handler() Python function performs the same role as the request logic in the previous applications. For CreateMessageItem it retrieves the request body from the event passed from API Gateway to the function. That data is passed to the _create_item() Python function, which is the business logic that does the work of creating the item in DynamoDB. You don’t have to, but I like to keep the split between request and business logic even in Lambda functions. I do this not just because it makes it easier for me to distinguish between the two but, more importantly, it makes it easier to change or even add new event handlers as the requirements of the application evolve. In the next blog post we’ll change the event source for some of the serverless functions which will require us to refactor the handler() code.
As we break down the monolith’s code into functions, we’re left with some leftover code, specifically the code that lets us properly serialize a DynamoDB item into JSON. To handle that, a Python package exists in src/common/ where common code can be placed.
src/common/common/__init__.py
'''Common code for DDB'''
from decimal import Decimal
from json import JSONEncoder
class DecimalEncoder(JSONEncoder):
'''Convert decimal values returned by boto3 DDB deserializer'''
def default(self, obj):
if isinstance(obj, Decimal):
return int(obj)
return super(DecimalEncoder, self).default(obj)Each Lambda function includes this package in its requirements.txt file so it’s bundled as an application dependency just like any other application dependency.
Moving To Asynchronous Event-Driven
Evolving our application to a serverless architecture doesn’t stop here. Everything we’ve done so far has been to handle synchronous requests. But it’s possible not all the application’s operations need to be done synchronously. In the next blog post, we’ll evolve this application into an event-driven application that can handle events asynchronously.
Continue on to Part 5 of the series, Asynchronous Event-Driven Functions. There we'll evolve this application to its final form..