 Tom McLaughlin
Tom McLaughlin

This is Part 3 of the series Hello Serverless, a guide aimed at the individual or team that is building their first serverless application. This series addresses the common conceptual and tactical questions that occur during the serverless development and operational lifecycle. This post covers the Hello Serverless application’s evolution from a Python Flask application meant to run on a host or in a container to a serverless monolith.
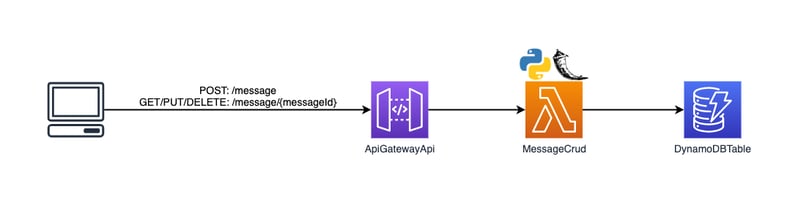
The Hello Serverless application has started off as a familiar-looking Python Flask application. Now it’s time to take the application serverless. We’ll do so by turning this application into a serverless monolith. We’ll use AWS API Gateway to replace the web server, and we’ll run the application in a single AWS Lambda function.
This is what the new serverless monolith will look like, and the code for the application can be found here on GitHub.
Before we go further, the term “function” can be confusing when discussing serverless. A serverless platform like AWS Lambda uses the term function to represent the unit of compute for the platform. We don’t talk about running VMs or containers, we talk about executing functions. An AWS Lambda function is composed of one or more code functions written, in our case, in Python. To ensure clarity, I’ll use the terms serverless function or AWS Lambda function to indicate the unit of compute for our serverless runtime platform, and code function or Python function when referring to application code.
What Is A Serverless Monolith?
A serverless monolith, sometimes called a lambdalith or monolambda, is a single serverless function that performs multiple types of operations. This is in opposition to using separate serverless functions, the topic of the next post in this series, for each of those operations. In our case, we will have a single function that handles create, retrieve, update, and delete operations. A serverless monolith is not to be confused with an application monolith, it can be an application monolith, but it can also be an application microservice. The easiest way to create a serverless monolith is through a lift and shift to a serverless platform, as we’ll perform here.
There are two primary benefits of a serverless monolith over separate serverless functions: possible productivity gains due to developer familiarity and reduced system complexity. While much is made about productivity gains by adopting serverless functions, the pattern is still new to many developers and requires ramp-up time. A serverless monolith, depending on the application, can look very similar to a non-serverless version of the same application. Also, similar to the debates over complexity between monolithic and microservices applications, the same debate exists over serverless monoliths versus separate serverless functions.
Serverless monoliths are not without their drawbacks. But these drawbacks are better understood as failures to reap the benefits of having multiple serverless functions as opposed to non-serverless alternatives. First, routing logic still needs to be written in the application. Second, understanding application performance will require application instrumentation to understand performance based application operation as compared to each operation being a separate serverless function. And lastly, the serverless function’s security permissions will need to be scoped to all possible permissions required instead of narrowing permissions on a per serverless function basis.
Creating A Serverless Monolith
To build our serverless monolith, we’re going to use AWS API Gateway and a single AWS Lambda function to communicate with DynamoDB. API Gateway is a managed service that lets us define and present HTTP APIs. It replaces our web server, such as Gunicorn, in the previous Python Flask application. It will also start to take over some of our route definition setup, though it’s not as obvious in a serverless monolith as it will be later when the application is decomposed into multiple functions.
Lambda is a serverless compute platform that provides the resources to run the Hello Serverless application. We’ll use Lambda as opposed to using a host instance or container runtime platform as we might with the Python Flask application. Our single Lambda function will be the Python Flask application from the previous example with minimal changes.
Our new application structure is arguably more fitting for an AWS Lambda function and is reflective of how I structure larger applications. It looks as follows.
./
├── LICENSE
├── Makefile
├── Pipfile
├── Pipfile.lock
├── README.md
├── diagram.png
├── events
│ ├── CreateItem-event.json
│ ├── CreateItem-msg.json
│ ├── DeleteItem-event.json
│ ├── DeleteItem-msg.json
│ ├── RetrieveItem-event.json
│ ├── UpdateItem-event.json
│ └── UpdateItem-msg.json
├── pytest.ini
├── samconfig.toml
├── src
│ └── handlers
│ └── MessageCrud
│ ├── app
│ │ ├── __init__.py
│ │ ├── models
│ │ │ ├── __init__.py
│ │ │ └── message.py
│ │ └── routes
│ │ ├── __init__.py
│ │ └── message.py
│ ├── function.py
│ └── requirements.txt
└── template.yamlThe app module from the Python Flask application has been moved from app/ to src/handlers/MessageCrud/app/ and the wsgi.py file at the root of the application has been moved to src/handlers/MessageCrud/function.py.
You don’t have to structure your serverless monolith this way but I do so on purpose here. This application uses a tool called AWS SAM CLI to manage packaging and deploying it. The tool packages AWS Lambda functions into separate deployables, which can reduce the size of each deployable. For that reason, I have all the application’s code under src/handlers/MessageCrud/, where MessageCrud is the name of the AWS Lambda function. Additionally, there is a handlers/ directory in anticipation that under src/ we may need a place for common code used across functions. None of this is necessary now, but when refactoring from a monolith to functions we will find this structure useful.
Additionally, AWS SAM CLI drives the application’s configuration and deployment through the template.yaml file in the root of the directory. The AWS SAM configuration language is an extension of AWS CloudFormation that makes working with serverless applications easier. In a later application iteration, we’ll see application code replaced by configuration in this file.
Finally, we’re using the flask-lambda module to essentially lift and shift our Python Flask application to AWS Lambda. I chose this module because it reduces the amount of code changes between the Python Flask app and this serverless monolith. If you have an existing Python Flask application, then try it or one of its forks out for a quick migration. However, I’ve never run large production workloads using this module to tell you how it will perform. If you’re choosing to write a Python serverless monolith from scratch or willing to spend some brief time learning a new framework, take a look at Chalice or Zappa. Both will be familiar if coming from building Flask applications. If you come from the JavaScript world, you might look at ClaudiaJS or Middy.
Application Initialization
The wsgi.py file has been renamed function.py. The file was renamed because it’s no longer the entry point to our WSGI web server. Instead, it’s the entry point for our AWS Lambda function. The code is otherwise unchanged from the previous application. If you’re familiar with Python, you might be tempted to name the file __init__.py and turn MessageCrud into a Python package, but that will not work. A Python AWS Lambda function’s handler configuration must be in the form of filename.function_or_variable where the .py suffix has been dropped from the filename.
The app/__init__.py file has only two lines of changes. Instead of using the Flask class from the flask module, we import the FlaskLambda class from the flask_lambda module, which provides a wrapper around the Flask class.
--- python-flask-hello-world/app/__init__.py 2020-04-25 19:16:08.000000000 -0400
+++ serverless-hello-world-monolith-py/src/handlers/MessageCrud/app/__init__.py 2020-04-26 10:59:19.000000000 -0400
@@ -2,7 +2,7 @@
'''Application entry point'''
import os
-from flask import Flask
+from flask_lambda import FlaskLambda
def _initialize_blueprints(app) -> None:
@@ -11,9 +11,9 @@
app.register_blueprint(message)
-def create_app() -> Flask:
+def create_app() -> FlaskLambda:
'''Create an app by initializing components'''
- app = Flask(__name__)
+ app = FlaskLambda(__name__)
_initialize_blueprints(app)
Lastly, what starts this application? There is no web server to be launched like gunicorn was used to launch the Python Flask application. Instead, we’ll configure an API Gateway resource and define an API Gateway event in our SAM template. API Gateway will be our web server and will run after it has been deployed in AWS.
The first block of configuration to look at in the template.yaml file is for the API Gateway.
ApiGatewayApi:
Type: AWS::Serverless::Api
Properties:
StageName: prodThe first resource is an AWS::Serverless::Api type resource named ApiGatewayApi, and there’s a property set called StageName, which is optional but I prefer to name it instead of using the default value.
The next configuration block in the file is for the MessageCrud function that is the application.
MessageCrudApp:
Type: AWS::Serverless::Function
Properties:
Description: "Message CRUD Application"
CodeUri: src/handlers/MessageCrud
Handler: function.handler
Runtime: python3.8
MemorySize: 128
Timeout: 3
Policies:
- Statement:
- Effect: "Allow"
Action:
- "dynamodb:PutItem"
- "dynamodb:GetItem"
- "dynamodb:UpdateItem"
- "dynamodb:DeleteItem"
Resource:
Fn::GetAtt:
- DynamoDBTable
- Arn
Environment:
Variables:
DDB_TABLE_NAME: !Ref DynamoDBTable
Events:
ApiGateway:
Type: Api
Properties:
Path: '{proxy+}'
Method: ANY
RestApiId: !Ref ApiGatewayApiThe CodeUri property is the directory path to the code, and the Handler property points to the function.py file’s handler variable defined in that file. In addition, there’s configuration for the compute runtime to use, the amount of memory to allocate, how long the function should run, IAM policy statements to allow DynamoDB operations, and environment variables for configuration such as the DynamoDB table to access.
Finally, there’s an Events property with an event we named ApiGateway of the type Api. The event’s configuration will forward every requested path for any HTTP method to the MessageCrud Lambda function. We’ll come back to this when we break down the serverless monolith in the next blog post. Instead of using a Path value of {proxy+}, we’ll use a URL path.
Route Definitions, Request Logic, & Business Logic
The code for the application’s route definitions, request logic, and business logic is entirely unchanged! Just by adjusting the interface slightly between our “web server” and our web application, our application works with no further changes.
Breaking Down The Monolith
What we’ve just done is effectively performed a lift and shift of a Python Flask application to API Gateway and Lambda to turn it into a serverless application. This is a pattern you can use to get very quick serverless wins. Our next post will cover breaking down the serverless monolith from a single serverless function into multiple serverless functions.
Continue on to Part 4 of the series, Serverless Functions. There we'll break down the serverless monolith into individual serverless functions.