 Tom McLaughlin
Tom McLaughlin


Our ApplicationCostMonitoring nanoservice is now a featured app in AWS Serverless Application Repository under Logging and Monitoring!
With AWS Serverless Application Repository (SAR) going general availability, we've reached a significant milestone for serverless. SAR facilitates a significant leap in how we will build applications in the coming years. It lets us release reusable domain logic — nanoservices — that we can use to compose our own functional applications. Over the past few weeks I've found I'm not alone in this thought. I’ve talked with or seen multiple people independently arriving at similar conclusions.
We are approaching the @swardley theory of composable services a hell of a lot faster than I thought we would. For instance, we needed usage limits on appsync. We just put APIG in front of appsync and done. Absolute madness. Serverless == Composable Services.
— Jared Short (@ShortJared) March 17, 2018
New #blog entry recapping last week's Twitch livestream and why I think #serverless applications and the Serverless Application Repository will change the way we develop applications. Let me know what you think! https://t.co/bFclvgdz5A
— James Hood (@jlhcoder) March 19, 2018
People are beginning to want to search for domain logic, either open source or inner source code, in the same way they use GitHub, NPM, PyPi, etc. Achieving the ability to easily search for high level code that can be assembled to form usable applications with minimal extra coding effort will have a significant impact in the rate at which we can deliver new services in our environment.
What Is a Nanoservice?
Let’s start with a definition of what a nanoservice is. You may see the term and think it’s just a microservice that has been broken down into very small pieces. With such a loose definition you end up just quibbling over size. Instead, let’s assign some more definitive characteristics.
A nanoservice is:
- Deployable
- Reusable
- Useful
A nanoservice being deployable means it also contains the infrastructure definition for itself that can be used by tooling to deploy the service. This definition handles every resource within the nanoservice’s boundaries. At its boundaries, the nanoservice can be told where to find another nanoservice, eg. a parameter value to help it find the event source in another nanoservice that will produce a trigger, and at the other end it will export resource information to allow another service to use it, eg. an event source name another nanoservice can use.
A nanoservice should be reusable. It should not necessarily be tied to its current use case. However, this characteristic may be challenging in light of the last characteristic, but there is nothing that should inherently keep it from being reusable except the imagination to build a different application.
Finally, the service is useful. In particular, it has domain logic that solves a problem or does something. This differentiates it from a generic software library. Boto 3 is a library that gives you the ability to interact with AWS and for instance fetch an S3 object. A nanoservice on the other hand when triggered, knows what object to fetch, the format of the data in order to parse it, and publish that data so another nanoservice may consume it. All the while, handling mundane details like error handling. To me, the usefulness is what distinguishes a nanoservice the most. A person needs only to deploy and potentially combine it with another nanoservice in order to see value.
Two characteristics I do not list are “usable” and “does only one thing”. A nanoservice may be usable on its own but it doesn’t have to be. Trying to make a nanoservice usable on its own may hamper it’s reusability and defeat the purpose. Additionally, I don’t want to get into arguments over whether a set of functions that provide get, set, and search for datastore objects is three nanoservices or one nanoservice that provides an interface to a datastore. Just use your best judgement and organize your code accordingly.
A nanoservice is more complex than a software library but less so than the average microservice. In the end you should be able to take nanoservices and group them together to form a usable application. A nanoservice is reasonably different enough to be its own thing, and warrant its own distinct term rather than reusing other common terms.
My Road To Discovering Nanoservices
I came to realize the power of nanoservices while building a small application to monitor AWS Cost and Usage reports which I also wanted to open source so others could use it. This service is called ApplicationCostMonitoring (ACM).
For a while, I’ve been fascinated about how transformative Lambda’s consumption-based billing will be.
X: I don't get why billing per function is such a big deal.
— swardley (@swardley) March 10, 2018
Me: Many in 2007 didn't understand why compute as a utility (i.e. EC2) was a big deal. They thought it was just about cheaper servers. They missed the entire point. You're doing the same with serverless.
Consumption-based billing (compared to capacity-based billing) will provide much finer-grained system cost data, which allows us to assign a direct cost to any change to a running system. Years from now, I believe we’ll even be monitoring cost as a system metric just as we do current performance metrics.
To facilitate exploring that idea, I started building an application to begin giving me the ability to analyze the AWS Cost and Usage report for my accounts. The application would do the following:
- Trigger by the delivery of a billing report
- Parse the report into individual line items
- And write them to a datastore or platform for analysis
My initial diagram looked roughly like this.

Figuring out what the analysis platform would be was hard to settle, but I just wanted to stop staring at a CSV file so I could start understanding the data I had. I ended up settling on S3 and AWS Athena as a start, and knowing I would probably move on from that, I used an SNS topic to separate the function that reads the billing report from the function that writes to S3. That would mean when I wanted to move onto a new analysis platform, I wouldn’t have to refactor the function that reads the billing report. What I had now was this:
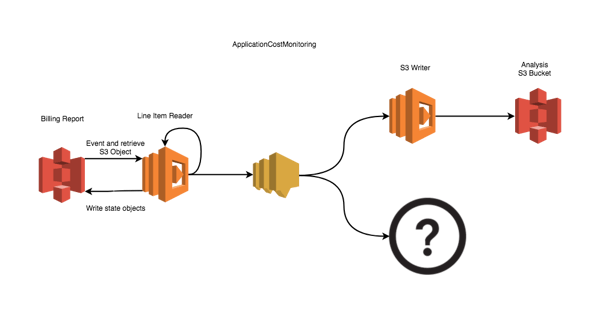
Looking at this diagram, I realized I needed to break the application down into smaller, independent pieces. What if a user actually found Athena useful for their needs? What if they preferred to use something different than what I settled on? I didn’t want to maintain multiple applications that were all half the same code or watch a proliferation of forks if others found this interesting. There had to be a way to make the core valuable code reusable while other code code be swapped and replaced for personal preference.
This is when I made the decision to release my application as independent pieces to SAR. It honestly look me awhile to make this decision too. It felt weird
Breaking My App Into Nanoservices
I went ahead and broke down ApplicationCostMonitoring into smaller pieces. What I now had were two services: one that was trigger by S3 events and would retrieve a billing report, parse, and publish line items, and a service that would write a line item to S3 so it was searchable with Athena.
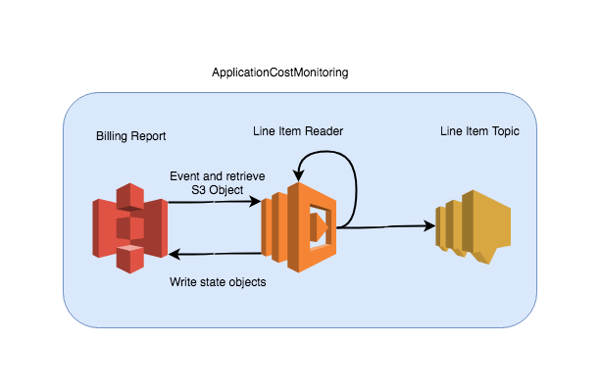
ApplicationCostMonitoring is not usable on its own. But it is useful, deployable, and reusable.
“So what, I could have written this in an hour?”
No, you couldn’t. The service contains knowledge learned by studying the AWS Cost and Usage report, experimenting and testing. Much of what I learned isn’t documented by AWS. Something I discovered purely by accident. While the code of the service may be simple, it is the product of studying and understanding a particular problem area. This is the unseen effort and labor that is often hard for us to reflect in our engineering.
ApplicationCostMonitoring contains domain logic that understands the idiosyncrasies of the AWS Cost and Usage report. The Cost and Usage reports produced are cumulative within a billing period, and due to the size of the report, ApplicationCostMonitoring keeps track of what records have already been published so that the report can run in both a timely and less costly manner. The service is also aware that report line items aren’t sorted entirely chronologically so it uses latest date seen instead of report position to figure out where to pick back up on the next run. It also knows to always reprocess the items from the first of the month because those items can and do change throughout the month.
The service also lets you handle report schema changes. These occur through making changes to the tags tracked in the report. These schema changes can cause issues for example with Athena and render your data unsearchable. Additionally, changing the tags and ultimately the schema will cause new line item IDs to be generated for some, but not all, charges in the report. All this is documented and you can decide to configure the service to run in the manner that best fits your needs.
This service does not have value because of the code, but because of its ability to solve a problem and the knowledge of the problem space that is embodied in the code. Someone does not need to go through what I’ve already gone through to properly analyze their AWS Cost and Usage report; they can use my work. This is where we are trending in the building of applications and systems, reusable domain logic to solve problems.
How Does AppRepo Facilitate Nanoservices and Serverless?
The general availability of AWS Serverless Application Repository represents a significant moment for the advancement of using nanoservices. It starts to help solve one of the biggest problems in this area: discoverability of nanoservices. How does someone know that ApplicationCostMonitoring exists, and has solved a problem of theirs already? This is why I published ApplictionCostMonitoring to SAR.
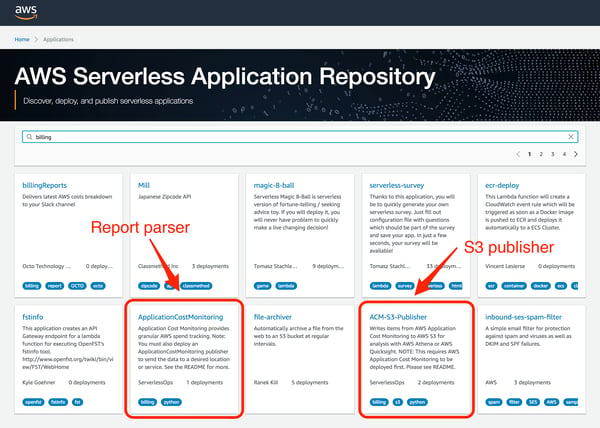
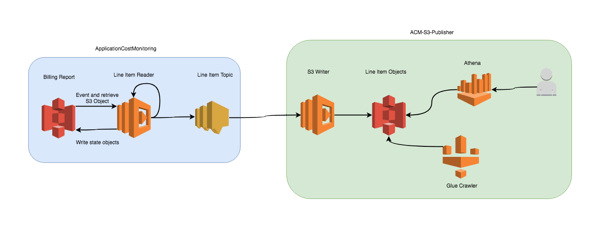
Having published ApplicationCostMonitoring and multiple publisher nanoservices to SAR, others can now find them, and compose their own system for analyzing their AWS spend. People can use them to compose an application that fits their needs. Even more exciting is they can use my nanoservices to build applications I never thought of or even imagined, and they’re free to focus more time and energy on the things I haven’t imagined instead of solving the problems I’ve already solved. Not reinventing the wheel, if you will.
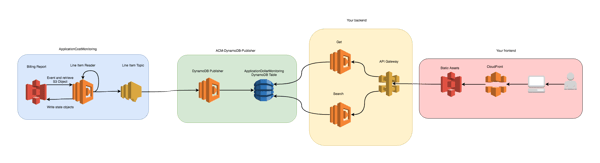
ApplicationCostMonitoring with S3 publisher and Athena
ApplicationCostMonitoring with DynamoDB powering a web application.
I’m not the only person seeing the power of nanoservices, either. See AWS developer James Hood’s aws-serverless-twitter-event-source and this recent Twitch broadcast on publishing and deploying serverless apps. In the coming weeks, I plan to look at using aws-serverless-twitter-event-source to build a Twitter bot. This is a radically different application than his leaderboard application, and I am free to spend more of my time focusing on what differentiates my application from his than figuring out how to work with the Twitter search API.
This is an exciting time; we are at the precipice of seeing a new way to build applications.
“One of the problems with the old object oriented world was there was no effective communication mechanism to expose what had been built. You’d often find duplication of objects and functions within a single company let alone between companies. Again, exposing as web services encourages this to change. That assumes someone has the sense to build a discovery mechanism such as a service register.” - Simon Wardley
Composing Serverless Applications Tomorrow
Building applications by composing reusable nanoservices of useful domain logic is new, and we’re a long way off from this being mainstream. Nanoservices themselves are also limited by the tools we currently have available. We have tools for building serverless applications and tools for building serverless nanoservices. We do not have the tools yet for building applications from nanoservices. SAR is a start, but we still lack good dependency management, tools that can show us the relationships between nanoservices and all the components of an application as well as tools to track changes to dependencies and prevent us from deploying breaking changes unknowingly. SAR also currently has its own limitations. It supports only a subset of AWS resources and the repository is still small.
However, there are people actively interested in composing applications with nanoservices, and working to make it happen.

What we’re seeing right now is the beginning of a dramatic shift in how we will be building applications for many years to come.
Is your organization interested in adopting serverless? See our DevOps transformation and AWS cloud advisory services.