 Tom McLaughlin
Tom McLaughlin

This is a continuation of our “Serverless DevOps: What Happens When the Server Goes Away?” series on defining the role of operations and DevOps engineers when working with serverless infrastructure.
For years, as a part of DevOps we’ve talked about infrastructure as code. As operations we went from hand building systems to automating the work with code. In some cases we even gave software developers access to build their own systems. It has become an integral part of DevOps, but have you thought about what infrastructure as code means, how it’s maybe changed, and what it means to implement in a serverless environment?
What is Infrastructure as Code?
At the highest and most generic level, infrastructure as code can be defined as the following:
The provisioning of computer and related resources, typically by IT operations teams, as code as opposed to human provisioning by that IT operations team.
It is code that lets us setup a server. It’s code that lets us define and provision an autoscaling group. It’s code that deploys a Kubernetes cluster or Vault.
That sort of definition is certainly correct, but it leads operations engineers to the wrong conclusions about what their own value is; it promotes the idea that our greatest value is performing engineering work. It promotes the idea that the value of operations is mostly in executing work.
I don’t like this devaluation of operations.
Too many operations engineers fall into this trap of believing their value is building infrastructure and keeping it running. This is a problem when we’re looking at more infrastructure work being assumed by public cloud providers. What do you do when AWS is able to provide a container management platform or secrets management just as well as, and faster than you can?
Instead, here is what I’d like to use as an updated definition:
The distillation of operational knowledge and expertise into code that allows for someone (who may not be the code author) to safely provision and manage infrastructure.
There are two aspects of that definition which I think set it apart from the previous.
First, “distillation of operational knowledge and expertise”. It is not the ability to deploy or setup something. It’s not the ability to automate the deployment of Kubernetes or Vault (Nothing against Kubernetes or Vault, these are just things I know people like to set up). The average engineer can probably accomplish that in a weekend if they wanted to. The value of an operations engineer is in being able to set up a service in a manner that is manageable, reliable, and maintainable. This is the expertise we have gained through experience, practice, and continuous learning. It is what separates us from those who are inexperienced in our field.
The second important part of that definition is “someone (who may not be you)”. The ability to setup or configure something is undifferentiated labor. There’s nothing special about the ability to setup a computer system. This work most engineers can accomplish in a weekend. When I first started to learn about infrastructure as code and infrastructure automation, the most exciting prospect to me was the ability to let someone else do this undifferentiated work. If you’ve automated your infrastructure but you are still required to click a button when someone else requests resources, you’re still relying on that undifferentiated work as your value. You’ve just gone from being a manual bottleneck in service delivery to an automated one.
Anyone with enough time and effort can read documentation and figure out how to automate the deployment of something. As operations engineers, we need to focus on the things not always mentioned in the documentation and what we’ve learned through experience.
That is what we need to turn into code.
Infrastructure as Code Today
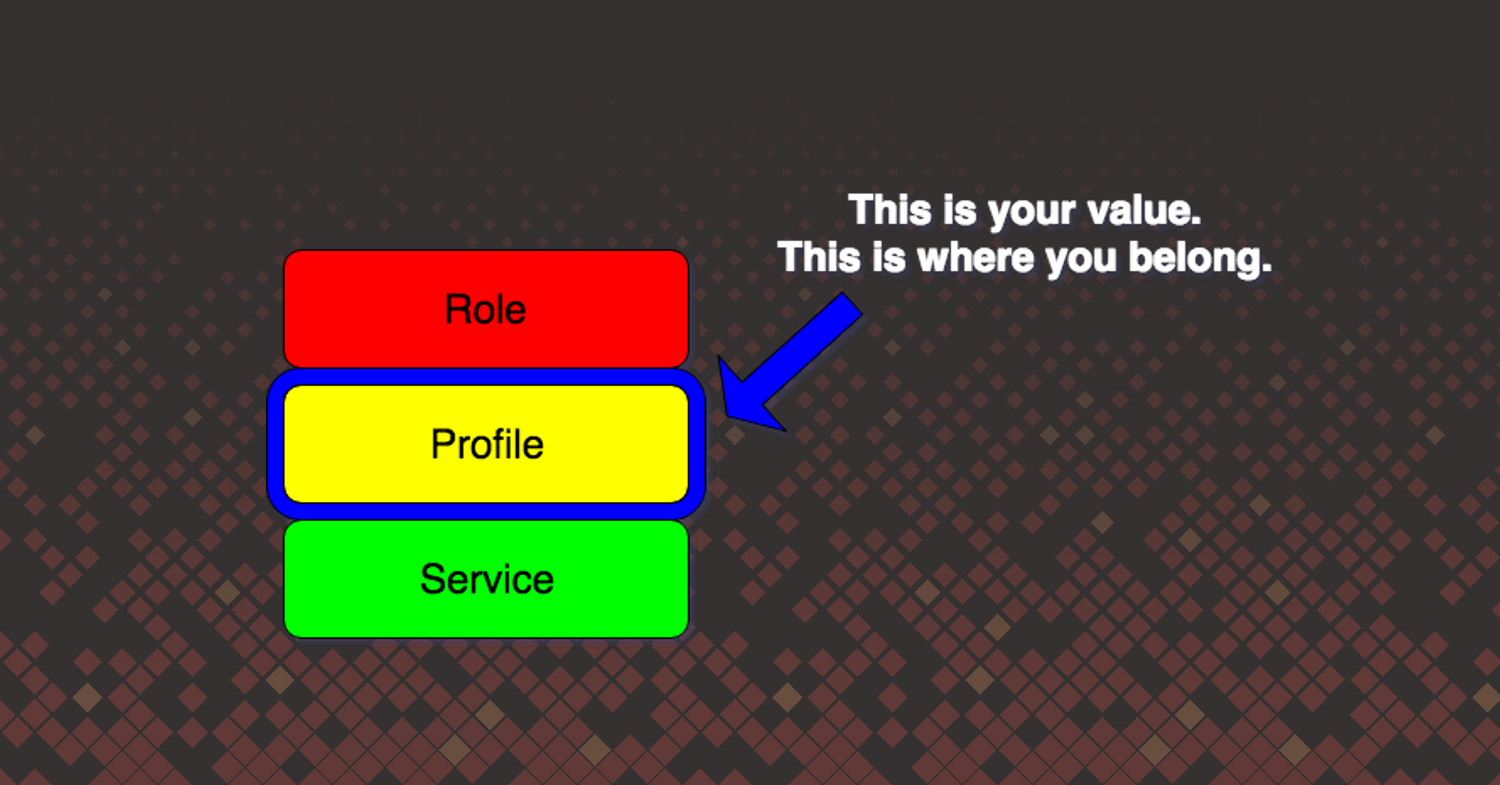
When discussing infrastructure as code today, we often think of Puppet, Chef, etc. for managing our host infrastructure. In the Puppet infrastructures I managed, we used the Puppet roles and profiles pattern. (If you’re a Chef user, the pattern is Chef wrapper cookbooks.) We divided configuration management into three layers of classes:
- Role class
- Profile class
- Service class
At the bottom was the service class, which considered undifferentiated labor. For almost everything we needed, there existed a Puppet module on Puppet Forge. This code was not special or unique to our organization, and we felt that recreating the pattern below with this Nginx class, when a suitable module already existed, was not worth our time.
class nginx {
package { 'nginx':
ensure => present
}
file { '/etc/nginx/nginx.conf':
ensure => present,
owner => 'root',
Group => 'root',
Mode => '0644',
source => 'puppet:///modules/nginx/nginx.conf',
require => Package['nginx'],
notify => Service['nginx']
}
service { 'nginx':
ensure => running,
enabled => true,
}
}
Not to mention, often the person who wrote the Puppet Forge module demonstrated a level of understanding of the service beyond what we possessed. Of course at times, we forked the module if we took issue with how it worked or saw bugs. But this was ultimately code we didn’t want to write or own.
In the middle of those classes was the profile class; this was the most important class to us in operations. The profile class was where we turned our operational knowledge into infrastructure code. This required me to understand both Nginx and its context within my organization. Coding the my::nginx class below was a better use of our time.
class my::nginx {
# From Puppet Forge module
class { '::nginx': }
# Status endpoint for Sensu Check
nginx::resource::server { "${name}.${::domain} ${name}":
ensure => present,
listen_port => 443,
www_root => '/var/www/',
ssl => true,
ssl_cert => '/path/to/wildcard_mydomain.crt',
ssl_key => '/path/to/wildcard_mydomain.key',
}
nginx::resource::location { "${name}_status":
ensure => present,
ssl => true,
ssl_only => true,
server => "${name}.${::domain} ${name}",
status_stub => true
}
# Sensu checks
package { 'sensu-plugins-nginx':
provider => sensu_gem
}
sensu::check { 'nginx-status':
handlers => 'default',
command => 'check-nginx-status.rb -p 443',
custom => {
refresh => 60,
occurrences => 2,
},
}
# Log rotation
logrotate::rule { 'nginx_access':
path => '/var/log/nginx/access.log',
rotate => 5,
rotate_every => 'day',
postrotate => 'service nginx reload',
}
logrotate::rule { 'nginx_error':
path => '/var/log/nginx/error.log',
rotate => 5,
rotate_every => 'day',
postrotate => 'service nginx reload',
}
}
The Puppet class above leaves the package, config, and service pattern work to a module from Puppet Forge. I spent my time instead building a Puppet class that consumed what was obtained from Puppet Forge and added my knowledge of running reliable services and Nginx to it.
The Nginx server forces SSL and points to the location of our SSL certificates on the host because we don’t allow unencrypted web traffic in the infrastructure. The my::nginx class adds a status check endpoint using a native Nginx capability and installs a Sensu plugin to check the endpoint because we use Sensu for monitoring. Lastly it configures log rotation to help prevent the host’s disk from becoming full. A check for disk space would already be configured on all hosts as a part of the standard OS setup.
Finally, at the top was the role class. This was a collection of profile classes. A role class represented a business function. We didn’t deploy nginx, we deployed a web application that was served up by Nginx. Our goal with role classes was to provide the ability to quickly put one together composed of profile classes and deploy a new service. All the while, we could maintain a high degree of confidence in success because of the work we put in at the profile layer to create a manageable, reliable, and maintainable service. Unlike other organizations, we didn’t want operations to be thorough gatekeepers.
Your job as an ops engineer is to distill your expertise into code at the profile (Puppet), wrapper (Chef) level, or whatever middle abstraction layer that exists in your tooling.
That is what we did above at the profile layer. We understood the operational issues around Nginx and web servers, and handled them with Puppet code. We did this by setting reasonable defaults, ensuring proper monitoring, and added configuration to prevent a foreseeable issue. This is valuable work. This is a combination of work that can’t be readily found on the internet because of your unique requirements, and work that incorporates your particular valuable skills as an operations engineer.
Infrastructure as Code in AWS
Let’s now take a look at infrastructure as code in the AWS management space. Let’s establish two things up front:
First, AWS provides a configuration management system called CloudFormation, which provides the ability to configure any AWS resource already. There is no work for you to perform in order to give someone the ability to create an S3 bucket with CloudFormation. This is roughly equivalent to AWS owning the service level work.
Second, with the infrastructure definition living with the application code, a developer doesn’t need you in order to create changes to their application. This is roughly equivalent to developers fully owning the role layer now.
Much of the undifferentiated work of infrastructure as code when you get to AWS doesn’t even exist as an option for you to perform, and your ability to be a gatekeeper becomes substantially limited. We need to define what that profile layer work looks like with CloudFormation. What does turning our operational expertise into code mean when going managing AWS resources and going serverless?
We can start with a basic SQS resource.
Resources:
MyQueue:
Type: "AWS::SQS::Queue"
This is the least amount of CloudFormation required to provision an SQS queue. Now let’s begin adding our operational knowledge to create something that is manageable, reliable, and maintainable. mIf you’re familiar with CloudFormation you may see some issues in the proceeding examples. We’ll get that afterwards.
Reasonable Configuration
We’ll begin by providing reasonable configuration of the SQS queue. In just about every organization, there exists rules about how services are implemented. Do you have a reason to enable server-side encryption across queues in your organization? If you do, you should probably not be leaving it up to every individual developer to remember to enable this. The CloudFormation to setup an SQS queue with server-side encryption should now look something roughly like this:
Mappings:
KmsMasterKeyId:
us-east-1:
Value: "arn:aws:kms:us-east-1:123456789012:alias/aws/sqs"
us-east-2:
Value: "arn:aws:kms:us-east-2:123456789012:alias/aws/sqs"
Resources:
MyQueue:
Type: "AWS::SQS::Queue"
Properties:
KmsMasterKeyId:
Fn::FindInMap:
- KmsMasterKeyId,
- Ref: "AWS::Region"
- "Value"
Setting the KMS key value is now handled automatically through a lookup based on the region the SQS queue is being created in. Neither the software engineer nor I need to worry about including this configuration.
Now move onto the MessageRetentionPeriod setting on the queue; the default value is four days. Think about that for a moment. Is that sort of timeout actually useful for you? Should you be failing faster and dropping the message to a dead letter queue so you can attempt to recover faster? Can a one size fits all value even be possible? Let’s add a configurable parameter with a reasonable default.
Parameters:
MessageRetentionPeriod:
Type: Number
Description: "SQS message retention period"
General: 1800
Mappings:
KmsMasterKeyId:
us-east-1:
Value: "arn:aws:kms:us-east-1:123456789012:alias/aws/sqs"
us-east-2:
Value: "arn:aws:kms:us-east-2:123456789012:alias/aws/sqs"
Resources:
MyQueue:
Type: "AWS::SQS::Queue"
Properties:
KmsMasterKeyId:
Fn::FindInMap:
- KmsMasterKeyId,
- Ref: "AWS::Region"
- "Value"
MessageRetentionPeriod:
Ref: MessageRetentionPeriod
We’ve added the MessageRetentionPeriod parameter with a 30 minute default. However, if a system requires a longer processing period or a faster failure the value is still configurable for these for outlier systems.
We’ve provided what we consider to be reasonable configuration of the SQS queue within our organization. We’ve done this in a manner that sets these values automatically so that we don’t need to think about this when creating a new queue.
Reliability
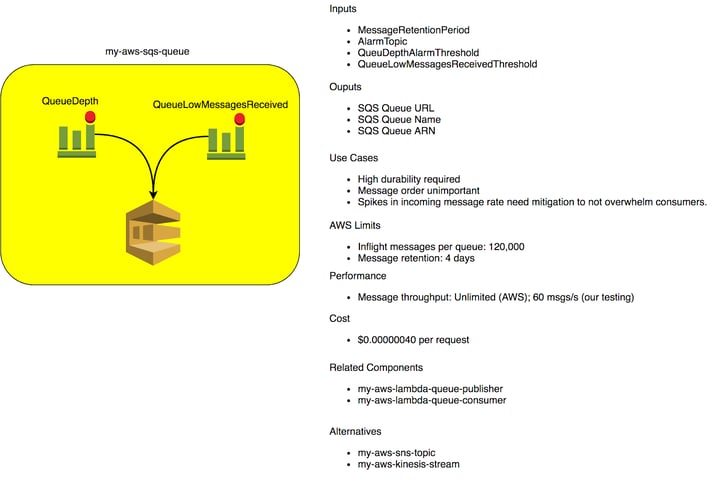
We can now move onto ensuring the reliability of the SQS queue. We’re not responsible for operating SQS; we’re responsible for ensuring the free and regular flow of messages through our application via an SQS queue. We’ll check for messages being produced onto the queue and for messages being consumed from the queue.
Parameters:
MessageRetentionPeriod:
Type: Number
Description: "SQS message retention period"
Default: 60
AlarmTopic:
Type: String
Description: "CloudWatch Alarms tpic name"
Default: "CloudWatchAlarmsTopic"
QueueLowMessagesReceivedThreshold:
Type: String
Description: "Low message alarm threshold"
QueueDepthAlarmThreshold:
Type: String
Description: "SQS queue depth alarm value"
Mappings:
KmsMasterKeyId:
us-east-1:
Value: "arn:aws:kms:us-east-1:123456789012:alias/aws/sqs"
us-east-2:
Value: "arn:aws:kms:us-east-2:123456789012:alias/aws/sqs"
Resources:
MyQueue:
Type: "AWS::SQS::Queue"
Properties:
KmsMasterKeyId:
Fn::FindInMap:
- KmsMasterKeyId,
- Ref: "AWS::Region"
- "Value"
MessageRetentionPeriod:
Ref: MessageRetentionPeriod
QueueLowMessagesReceived:
Type: "AWS::CloudWatch::Alarm"
Properties:
AlarmDescription: "Alarm on messages received lower than normal."
Namespace: "AWS/SQS"
MetricName: "NumberOfMessagesSent"
Dimensions:
- Name: "QueueName"
Value:
Fn::GetAtt:
- "MyQueue"
- "QueueName"
Statistic: "Sum"
Period: "300" # This is as granular as we get from AWS.
EvaluationPeriods: "3"
Threshold:
Ref: "QueueLowMessagesReceivedThreshold"
ComparisonOperator: "LessThanThreshold"
AlarmActions:
- Ref: "AlarmTopic"
QueueDepth:
Type: "AWS::CloudWatch::Alarm"
Properties:
AlarmDescription: "Alarm on high queue depth."
Namespace: "AWS/SQS"
MetricName: "ApproximateNumberOfMessagesVisible"
Dimensions:
- Name: "QueueName"
Value:
Fn::GetAtt:
- "MyQueue"
- "QueueName"
Statistic: "Sum"
Period: "300" # This is as granular as we get from AWS.
EvaluationPeriods: "1"
Threshold:
Ref: "QueueDepthAlarmThreshold"
ComparisonOperator: "GreaterThanThreshold"
AlarmActions:
- Ref: "AlarmTopic"
Two CloudWatch alarms, along with some parameters, have been added. The CloudWatch alarm QueueLowMessagesReceived checks to ensure that messages are being produced onto the queue. The new QueueLowMessagesReceivedThreshold parameter has no default and requires you to take a few moments to think about your system’s traffic pattern.
The QueueDepth CloudWatch alarm will alert if the number of approximate messages in the queue is above a given threshold, indicating that consumers are unable to keep up with the rate of messages. Additionally, the QueueDepthAlarmThreshold parameter does not have a default value in order to force you to think about expected message rates.
There’s also a parameter value used by both alarms to pass alarm state changes to an SNS topic. That SNS topic routes to your monitoring and alerting system to let you know when there is an issue with this SQS queue. You as an ops person should own that alerting pipeline in your environment.
We’re no longer deploying just an SQS queue now, we’re deploying a queue along with CloudWatch resources in order to help us maintain the reliability of this queue. This is just like adding the Sensu checks for the Nginx service in the Puppet example earlier. Most of all, this is applying our operational expertise in understanding how this service could fail in our application.
System Patterns
Lastly, providing resource patterns and an explanation of when to use the pattern is a part of the job of operations. When all you have is a hammer, everything becomes a nail. Preventing the misapplication of design patterns is something that we should be looking out for.
When do you use an SQS queue? What about SNS? Both together? And we haven’t even gotten to Kinesis. Sometime, the exact AWS resource patterns to use aren’t properly thought out. Engineers often end up reusing what they did last time because that’s what they know.
Right now, the options for this are a little limited, but we’ll discuss what is coming in the serverless tools ecosystem shortly to help us provide a library of patterns to help engineers to make the right choices.
State of AWS Tools
What I showed above may seem great, but it’s not immediately usable today. Remember: operations should be turning their knowledge into code that can be consumed by others. You could possibly achieve this with CloudFormation nested stacks, but you’d have to build your own registry of CloudFormation snippets and a discovery mechanism. If you’re familiar with CloudFormation you may have noticed this issue. Unlike the Puppet example earlier, there is no readily available means of providing an infrastructure as code profile layer for AWS services. Let’s talk about what we can do today and what’s coming.
What You Can Do Today with Serverless
If you’re looking for work to do today, then look at Serverless Framework. Serverless Framework’s tool provides the capabilities to make the most of your operational knowledge. Serverless Framework is based on top of CloudFormation so the syntax isn’t wildly different, and it adds several features that make it easier to work with.
Start with Serverless Framework’s plugin capabilities. This capability alone is one of the main reasons I love this tool for managing serverless applications. If your use case is common enough, then there’s a good chance a plugin may already exist. If a plugin doesn’t exist, learn the plugin API and write some JavaScript to make it exist.
In fact, the example CloudWatch alarm for QueueDepth was inspired by the serverless-sqs-alarms-plugin plugin which I regularly use. The plugin could also be extended to handle the QueueLowMessagesReceived alarm as well, and at some point I should submit a PR to extend it.
The down side of this approach is it requires someone to remember to add the plugin and configure it. You’d still need to perform code reviews to ensure the alarms are in place. However, the plugin does greatly reduce the amount of configuration that one needs to write. Just compare the following CloudFormation and Serverless Framework snippets.
CloudFormation:
QueueDepth:
Type: "AWS::CloudWatch::Alarm"
Properties:
AlarmDescription: "Alarm on high queue depth."
Namespace: "AWS/SQS"
MetricName: "ApproximateNumberOfMessagesVisible"
Dimensions:
- Name: "QueueName"
Value:
Fn::GetAtt:
- "MyQueue"
- "QueueName"
Statistic: "Sum"
Period: "300" # This is as granular as we get from AWS.
EvaluationPeriods: "1"
Threshold:
Ref: "QueueDepthAlarmThreshold"
ComparisonOperator: "GreaterThanThreshold"
AlarmActions:
- Ref: "AlarmTopic"
Serverless Framework:
custom:
sqs-alarms:
- queue: MyQueue
topic: AlarmTopic
thresholds:
- 100
Serverless Framework templates is a feature that I don’t think gets enough attention. I became tired of initialing a new AWS Lambda Python 3 project to be just the way I create my services, that I created my own template project. Now I can initialize a new project with the following:
serverless create -u https://github.com/ServerlessOpsIO/sls-aws-python-36 -p |PATH| -n |NAME|My AWS Lambda Python 3 template handles standard setup such as logging, project stage and AWS profile handling based on how I segregate stages and accounts, a plugin to handle Python dependencies, and a lit of standard dependencies required. Eventually I plan on adding a unit, integration, and load testing skeleton configuration. The purpose of all this is to provide the ability to quickly setup a project with best practices already established. I want to focus on the application and not all this boilerplate setup.
Additionally, I also have a template for creating an AWS S3 hosted website. I created this higher order application pattern because I find it usable enough and something I will probably wish to repeat.
What You Will Be Able To Do Tomorrow
What we’ll be able to do tomorrow is something I’m very interested in. Right now, there’s AWS Serverless Application Repository (SAR) and Serverless Framework’s Components. Both of these are great and nearly providing what I’m looking for.
I’ve talked about AWS Serverless Application Repository and nanoservices before. Right now, most people are publishing small fully working applications, but some of us have gone ahead and started to see what we can create. We’ve created nanoservices such as our service to parse the AWS Cost and Usage report, or a service from AWS to fetch tweets with a certain phrase or word from the Twitter stream. Eventually, you will be able to use SAR to construct applications. AWS SAR doesn’t yet have the ability to nest nanoservices, which is where the next tool appears to excel.
Just recently, Serverless Framework released Components. I’m excited for this! While similar to AWS SAR, it lets you nest components, which is key to recreating the roles, profiles, and services pattern of configuration management. Most of the current examples in the GitHub repository are higher order services akin to roles. The current components in the registry are limited, but I know they’re working on adding more. As the component registry grows, I can start combining them to create reusable resource patterns that require minimal configuration, but also provide flexibility to meet the needs of engineers.
With Serverless Framework Components, we will finally be able to empower developers to create an SQS queue with reasonable configuration and appropriate monitoring without the need for our regular oversight! As operations engineers, our work will continue with building out the library of patterns. It won’t just be documenting the inputs and outputs of the different patterns; instead, it’ll be documenting when the pattern should be used to satisfy technical concerns, as well as its impact on business concerns.
If you’re used to writing system documentation, writing architecture pattern documentation will be similar.
Conclusion
Your value is not in the setup of infrastructure. Your value is turning your operational knowledge and expertise into reusable code.
Have thoughts on this? Find me on twitter at @tmclaughbos, or visit the ServerlessOps homepage and chat via the website.